راهنمای کامل رگولار اکسپرشن – ریجکس
نوامبر 7, 2014تمرین هایی برای یادگیری رگولار اکسپرشن
نوامبر 7, 2014کاراکتر ها Characters
| کاراکتر | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| \d | در اکثر موتور ها: یک رقم. بین 0 و 9 | file_\d\d | file_25 |
| \d | .NET, Python 3: one Unicode digit in any script | file_\d\d | file_9? |
| \w | در اکثر موتور ها: یک حرف اسکی، عدد یا آندرلاین | \w-\w\w\w | A-b_1 |
| \w | .Python 3: “word character”: Unicode letter, ideogram, digit, or underscore | \w-\w\w\w | ?-?_? |
| \w | .NET: “word character”: Unicode letter, ideogram, digit, or connector | \w-\w\w\w | ?-??? |
| \s | Most engines: “whitespace character”: space, tab, newline, carriage return, vertical tab | a\sb\sc | a b c |
| \s | .NET, Python 3, JavaScript: “whitespace character”: any Unicode separator | a\sb\sc | a b c |
| \D | هر کاراکتری که عدد نباشد یعنی با بک اسلش دی کوچک تطابق نکند | \D\D\D | ABC |
| \W | هر کاراکتری که کلمه نباشد یعنی با بک اسلش دبلیو کوچک تطابق نکند | \W\W\W\W\W | *-+=) |
| \S | هر کاراکتری که فاصله و جدا کننده نباشد یعنی با بکسلش اس کوچک تطابق نکند | \S\S\S\S | Yoyo |
مقدار دهنده ها Quantifiers
| کمیت دهنده | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| + | یکی یا بیشتر | Version \w-\w+ | Version A-b1_1 |
| {3} | دقیقا سه تا | \D{3} | ABC |
| {2,4} | بین دو تا چهار تا | \d{2,4} | 156 |
| {3,} | سه تا یا بیشتر | \w{3,} | regex_tutorial |
| * | هیچی یا بیشتر | A*B*C* | AAACC |
| ? | یکبار یا بیشتر | plurals? | plural |
کاراکتر هايي ديگر More Characters
| کاراکتر | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| . | (هر کاراکتری بجز انتهای خط (لاین بریک | a.c | abc |
| . | هر کاراکتری بغیر از لاین بریک | .* | whatever, man. |
| \. | یک نقطه کاراکتر های خاص باید با بک اسلش اسکیپ بشوند |
a\.c | a.c |
| \ | اسکیپ کردن کاراکتر های خاص | \.\*\+\? \$\^\/\\ | .*+? $^/\ |
| \ | اسکیپ کردن کاراکتر های خاص | \[\{\(\)\}\] | [{()}] |
نشانه هاي منطقي Logic
| منطق | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| | | عملوند یا | 22|33 | 33 |
| ( … ) | گروه ذخیره شونده | A(nt|pple) | Apple (captures “pple”) |
| \1 | محتویات گروه 1 | r(\w)g\1x | regex |
| \2 | محتویات گروه 2 | (\d\d)\+(\d\d)=\2\+\1 | 12+65=65+12 |
| (?: … ) | گروهی که ذخیره نمی شوند | A(?:nt|pple) | Apple |
فاصله دهنده ها More White-Space
| کاراکتر | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| \t | Tab | T\t\w{2} | T ab |
| \r | Carriage return character | see below | |
| \n | Line feed character | see below | |
| \r\n | Line separator on Windows | AB\r\nCD | AB CD |
| \N | Perl, PCRE (C, PHP, R…): one character that is not a line feed | \N+ | ABC |
| \v | .NET, JavaScript, Python, Ruby: vertical tab | ||
| \v | Perl, PCRE (C, PHP, R…), Java: one vertical whitespace character: line feed, carriage return, vertical tab, form feed, paragraph or line separator | ||
| \V | Perl, PCRE (C, PHP, R…), Java: any character that is not a vertical whitespace | ||
| \R | Perl, PCRE (C, PHP, R…), Java: one line break (carriage return + line feed pair, and all the characters matched by \v) |
بیشتر دربارۀ کميت دهنده ها More Quantifiers
| کمیت دهنده | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| + | علامت پلاس زیاده خواه است | \d+ | 12345 |
| ? | جلوی زیاده خواهی را می گیرد | \d+? | 1 in 12345 |
| * | استریسک زیاده خواه است | A* | AAA |
| ? | علامت سوال جلوی زیاده خواهی را می گیرد | A*? | empty in AAA |
| {2,4} | زیاده خواه | \w{2,4} | abcd |
| ? | جلوگیری از زیاده خواهی | \w{2,4}? | ab in abcd |
کلاس هاي کاراکتر Character Classes
| کاراکتر | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| [ … ] | یکی از کاراکتر های موجود در براکت | [AEIOU] | One uppercase vowel |
| [ … ] | یکی از کاراکتر های موجود در براکت | T[ao]p | Tap or Top |
| – | مشخص کننده ی بازه | [a-z] | One lowercase letter |
| [x-y] | یکی از کاراکتر های موجود در بازه ی بین ایکس تا وای | [A-Z]+ | GREAT |
| [ … ] | یکی از کاراکتر های موجود در براکت | [AB1-5w-z] | One of either: A,B,1,2,3,4,5,w,x,y,z |
| [x-y] | یکی از کاراکتر های موجود در بازه ی بین ایکس تا وای | [?-~]+ | Characters in the printable section of the ASCII table. |
| [^x] | یک کاراکتر که ایکس نباشد | [^a-z]{3} | A1! |
| [^x-y] | یکی از کاراکتر هایی که موجود نباشد در بازه ی بین ایکس تا وای | [^?-~]+ | Characters that arenot in the printable section of the ASCII table. |
| [\d\D] | یک کاراکتر که عدد باشد یا غیر عدد باشد (همه چیز را بر می گرداند) |
[\d\D]+ | Any characters, inc- luding new lines, which the regular dot doesn’t match |
| [\x41] | کاراکتر 41 ام از جدول هگزادسیمال اسکی یعنی A |
[\x41-\x45]{3} | ABE |
مشخص کننده هاي مرز Anchors and Boundaries
| چنگک | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| ^ | Start of string or start of linedepending on multiline mode. (But when [^inside brackets], it means “not”) | ^abc .* | abc (line start) |
| $ | End of string or end of line depending on multiline mode. Many engine-dependent subtleties. | .*? the end$ | this is the end |
| \A | Beginning of string (all major engines except JS) |
\Aabc[\d\D]* | abc (string… …start) |
| \z | Very end of the string Not available in Python and JS |
the end\z | this is…\n…the end |
| \Z | End of string or (except Python) before final line break Not available in JS |
the end\Z | this is…\n…the end\n |
| \G | Beginning of String or End of Previous Match .NET, Java, PCRE (C, PHP, R…), Perl, Ruby |
||
| \b | Word boundary Most engines: position where one side only is an ASCII letter, digit or underscore |
Bob.*\bcat\b | Bob ate the cat |
| \b | Word boundary .NET, Java, Python 3, Ruby: position where one side only is a Unicode letter, digit or underscore |
Bob.*\b\?????\b | Bob ate the ????? |
| \B | Not a word boundary | c.*\Bcat\B.* | copycats |
کلاس هاي پوزيکس POSIX Classes
| کاراکتر | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| [:alpha:] | PCRE (C, PHP, R…): ASCII letters A-Z and a-z | [8[:alpha:]]+ | WellDone88 |
| [:alpha:] | Ruby 2: Unicode letter or ideogram | [[:alpha:]\d]+ | ?????99 |
| [:alnum:] | PCRE (C, PHP, R…): ASCII digits and letters A-Z and a-z | [[:alnum:]]{10} | ABCDE12345 |
| [:alnum:] | Ruby 2: Unicode digit, letter or ideogram | [[:alnum:]]{10} | ?????90210 |
| [:punct:] | PCRE (C, PHP, R…): ASCII punctuation mark | [[:punct:]]+ | ?!.,:; |
| [:punct:] | Ruby: Unicode punctuation mark | [[:punct:]]+ | ?,:?? |
تغییر دهنده های درون خطی Inline Modifiers
None of these are supported in JavaScript. In Ruby, beware of (?s) and (?m).
| تغییر دهنده | شرح | Example | Sample Match |
|---|---|---|---|
| (?i) | Case-insensitive mode (except JavaScript) |
(?i)Monday | monDAY |
| (?s) | DOTALL mode (except JS and Ruby). The dot (.) matches new line characters (\r\n). Also known as “single-line mode” because the dot treats the entire input as a single line | (?s)From A.*to Z | From A to Z |
| (?m) | Multiline mode (except Ruby and JS) ^ and $ match at the beginning and end of every line |
(?m)1\r\n^2$\r\n^3$ | 1 2 3 |
| (?m) | In Ruby: the same as (?s) in other engines, i.e. DOTALL mode, i.e. dot matches line breaks | (?m)From A.*to Z | From A to Z |
| (?x) | Free-Spacing Mode mode (except JavaScript). Also known as comment mode or whitespace mode |
(?x) # this is a # comment abc # write on multiple # lines [ ]d # spaces must be # in brackets |
abc d |
| (?n) | .NET: named capture only | Turns all (parentheses) into non-capture groups. To capture, use named groups. | |
| (?d) | Java: Unix linebreaks only | The dot and the ^ and $ anchors are only affected by \n |
جستجو کننده ها Lookarounds
| جستجوگر | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| (?=…) | Positive lookahead | (?=\d{10})\d{5} | 01234 in0123456789 |
| (?<=…) | Positive lookbehind | (?<=\d)cat | cat in 1cat |
| (?!…) | Negative lookahead | (?!theatre)the\w+ | theme |
| (?<!…) | Negative lookbehind | \w{3}(?<!mon)ster | Munster |
عملوند هاي کلاس کاراکتر Character Class Operations
| عملیات کلاس | شرح | مثال | نمونه تطابق |
|---|---|---|---|
| […-[…]] | .NET: character class subtraction. One character that is in those on the left, but not in the subtracted class. | [a-z-[aeiou]] | Any lowercase consonant |
| […-[…]] | .NET: character class subtraction. | [\p{IsArabic}-[\D]] | An Arabic character that is not a non-digit, i.e., an Arabic digit |
| […&&[…]] | Java, Ruby 2+: character class intersection. One character that is both in those on the left and in the && class. | [\S&&[\D]] | An non-whitespace character that is a non-digit. |
| […&&[…]] | Java, Ruby 2+: character class intersection. | [\S&&[\D]&&[^a-zA-Z]] | An non-whitespace character that a non-digit and not a letter. |
| […&&[^…]] | Java, Ruby 2+: character class subtraction is obtained by intersecting a class with a negated class | [a-z&&[^aeiou]] | An English lowercase letter that is not a vowel. |
| […&&[^…]] | Java, Ruby 2+: character class subtraction | [\p{InArabic}&&[^\p{L}\p{N}]] | An Arabic character that is not a letter or a number |



10 دیدگاه ها
اگر متوجه شدید که کاراکتری یا علامتی جا افتاده است، در کامنت ها معرفی کنید تا اضافه شود.
سلام .
سایت مطلب ارزشمندی نوشته بودید . ممنون .
یک سوال در رابطه با رجکس ها دارم :
چه طور می توانیم بگوییم سه حرف اول یا به ترتیب (به طور مثال) Aug باشد یا May و یا Jan ؟
من این رجکس را نوشتم که ظاهرا ایراد دارد :
[(?Jan)|(?Aug)|(?May)]
[(?Jan)|(?Aug)|(?May)]
درود شهریار جان. بدین صورت باید بنویسید:
([Jan]|[May]|[Aug])
سلام
من چندتا سوال داشتم.ممکنه کسی لطف کنه و جواب بدهد؟
(۱) Deletes all h’s (uppercase and lowercase) followed by a consonant except ‘y’; I.e.,
John -> Jon
Baht -> Bat
hot -> hot
Hyatt -> Hyatt
(2) Replace all double consonants with a single consonant.
Sally -> Saly
rabbit -> rabit
(3) Replace all a’s in a word to “eI” if the last letter of the word is an “e” and delete the last “e”.
Kate -> KeIt
bat -> bat
(4) Delete all non-alphanumeric characters
dog -> dog
d”o$%gq12 -> dogq12
در ایمیل پاسخ داده شد.
اگه امکانش هست جوابای سوالا رو برای منم بفرستید
با تشکر
ارسال شد، دوست عزیز!
سلام
ممنون می شم جواب سوال های بالا رو برای من هم ارسال کنید که بتونم چک کنم درست انجام دادم یا نه.
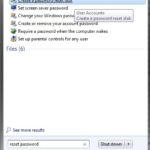
جواب های رگولار اکسپرشن رو در این صفحه قرار دادم:
http://q.neomarket.ir/34/%D8%B3%D9%88%D8%A7%D9%84%D8%A7%D8%AA+%D8%B1%DA%AF%D9%88%D9%84%D8%A7%D8%B1+%D8%A7%DA%A9%D8%B3%D9%BE%D8%B1%D8%B4%D9%86
اگر مشکلی بود توی پاسخ ها می تونید کامنت بگذارید.